
AI Agent 正在成为产品与组织的新变量,但关于它的误解也在迅速蔓延:它是工具?是助手?是“拟人化”的幻觉?本文从五个关键问题出发,拆解 AI Agent 的能力边界与协作价值,帮助你厘清认知、校准预期配资网址之家,并找到真正值得投入的方向。
 一、前言——LLM
一、前言——LLM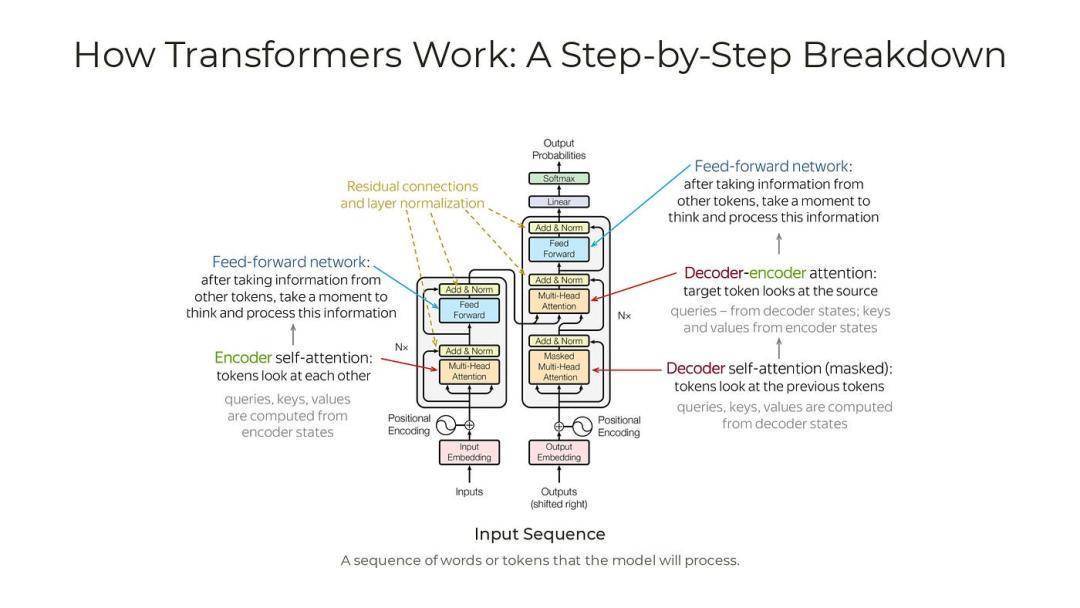
LLM的发展可以追溯到20世纪中叶的自然语言处理研究,但真正形成现代LLM的关键在于深度学习和大数据的结合。早期,语言模型主要基于规则系统和同级方法,例如n-gram模型(基于词频统计预测下一个词)。这些模型简单但是很局限,没有办法处理复杂的语义。
关键转折点:神经网络的兴起。20世纪80-90年代,递归神经网络(RNN)和长短期记忆网络(LSTM)的出现允许模型处理序列数据,但在长序列上易出现梯度消失的问题,导致很难去训练大规模模型。Transformer架构的诞生(2017年):这是LLM形成的里程碑。Google研究团队在论文《Attention Is All You Need》提出,Transformer取代了RNN,使用自注意力机制(Self-Attention)来并行处理序列提高效率和性能。在此基础上就使得模型能够处理更长的上下文,并能捕捉词与词之间的复杂关系。早期LLM如BERT(Google于2018研发)和GPT-1(OpenAI于2018开发)就是基于Transformer的变体。
 二、从LLM到AI Agent
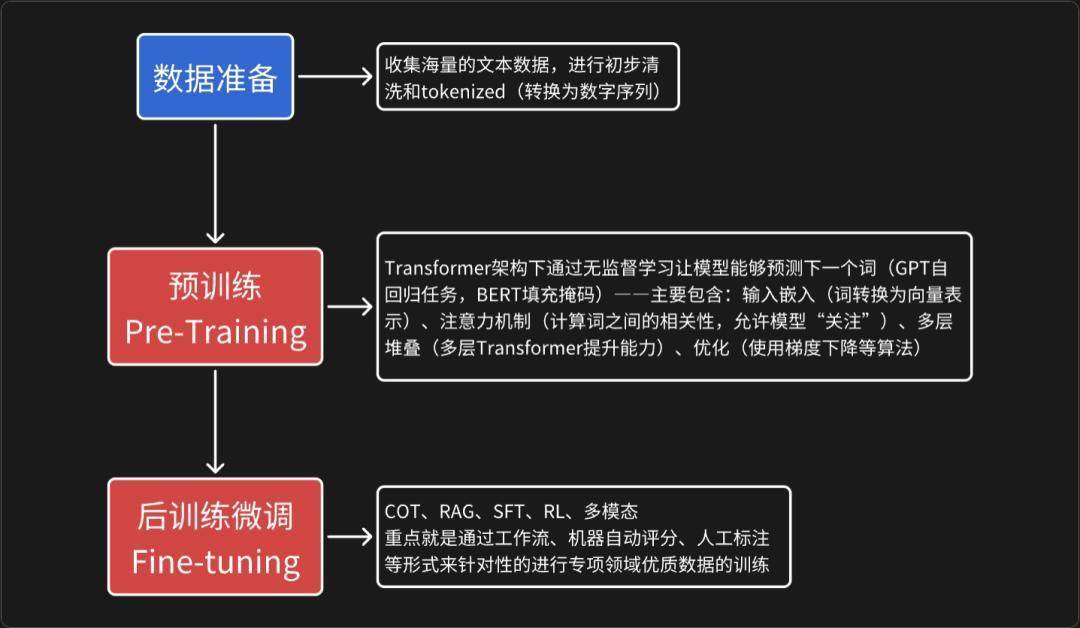
二、从LLM到AI AgentAI从被动响应系统向主动智能代理的转变,这一过渡源于LLM的核心局限性。LLM基于Transformer架构,如Decoder-Only模型,擅长处理序列数据并生成文本,但它们本质上是静态的预测引擎,仅靠预训练数据和上下文窗口(Contest Window)来输出响应,无法与外部环境交互或执行多步策略。这就催生出了AI Agent的定义:一个以LLM为基础模型(Foundation Model),集成规划、工具调用和反馈循环的自制系统,能够分解任务、调用外部API并迭代优化结果。(POMDPs中也提到,AI Agent旨在实现从L0到L5的自治水平)
LLM的局限性知识延后与实时性缺失:LLM的参数化知识没法访问动态信息,就容易导致幻觉。Agent通过Tool Calling API集成外部接口,从而能够拓展边界——经典的就比如RAG。被动响应与缺乏行动:LLM仅生成文本,不能执行操作进行交互。Agent引入Action Space的定义,使用ReAct或Plan-and-Execute框架,让LLM输出结构化行动——例如调用RESTful APIs。短期上下文与记忆不足:LLM的Attention Mechanism限制于固定窗口(例如Llama 3.1的128K),很容易导致灾难性遗忘(Catastrophic Forgetting)。Agent采用Long-Term Memory通过Episodic Buffers来支持持续学习而不是一次性的训练。单步骤 vs 多步骤:LLM擅长单词推理,但多步任务还是需要ToT(Tree)或GoT(Graph)来探索路径。Agent的必要性在于分层规划(Hierarchical Planning),通过支持反馈循环来处理不确定性——例如BabyAGI用MCTS模拟决策树。技术定义视角AI Agent基于2023 年 Yao 等人的《Reasoning and Acting》论文,可以形式化为一个元组{M,P,T,Mem,Exec}:
M是核心LLM;P是规划模块;T是工具集;Mem是记忆系统;Exec是执行引擎;不同于传统规则_based Agents(例如FSM聊天机器人),AI Agent强调自主性,利用LLM“涌现”的能力(比如In-Context Learing)学习而无需参数更新。LangChain Expression Language与Multi-Agent Conversation对于这一块的定义已经标准化了
以上提到的种种局限使得LLM在复杂场景中能力不足,但AI Agent通过集成这些技术实现了必要的“思考”到“行动”的转变。这一过渡不仅提升了效率,还引入了安全性考虑——例如Constitutional AI(Anthropic使用Self-Critique Prompts)能够确保Agent输出符合伦理规范。
三、有哪些关键组件AI Agent的“大脑”,负责处理自然语言输入、生成推理和决策输出。目前主流Mixture-of-Experts(MoE)架构(例如GPT-5、Grok4)通过动态激活专家子模块实现高效的推理,主要包含以下技术:Tokenization + Embedding、注意力机制、强化学习对齐(RLHF、DPO)
规划模块(Planning Module)负责任务分解、路径探索和动态调整,支持Agent从反应式转向主动式。核心是Reasoning Engine,通过CoT提示技术逐步生成思维链。今年ReAct(Reasoning and Acting)框架标准是最普遍的——交替进行推理和行动,再结合1Relection Prompting反思失败原因。
关键名词
任务分解:使用Decomposition 技术或Least-to-Most Prompting,把复杂目标拆分为子任务序列。
规则优化:集成GoT用图结构表示计划,支持并行探索;或者使用分层规划再多代理系统中分配角色。
适应性:通过奖励机制评估计划质量来自我修正
工具集Agent通过工具集获取了与外部世界交互的能力,核心是在于FunctionCalling或Tool Calling API(核心是通过JSON等结构化维护参数)——最近的比如OpenAI的Atlas,Perplexity AI。
记忆模块通过存储与检索上下文,长期的学习能够比买呢Agent重复工作。主要分为Short-Term Memory(基于LLM的Context Window)和Long-Term Memory(RAG)——核心是通过Fine-Tuning或In-Context Learning来更新记忆保存有价值的内容。
目前更多基于感知和执行的组件更多的在智能化原件上(智驾、机器人、陪伴娃娃),将更多的多模态数据与模型进行交互,这些是正在实时发生的改变。
四、Agent的工作流程本质上AI Agent是一个动态的、迭代的循环系统(常见架构LangGraph/AutoGen)
Observation:Agent 首先接收来自任务环境的输入或状态。这些环境可以多种多样,包括自然语言交互环境(例如问答任务),具身环境 (Embodied Environments)(例如机器人操作) 或Web 环境 (Web Environments)(例如网页购物Thought and Planning:此阶段主要依赖规划模块,其核心是推理引擎,通常由LLM-Profiled Policy (glmpolicy)扮演。glmpolicy 可以是执行器 (glmactor)(直接从状态映射到行动) 或规划器 (glmplanner)(生成一系列行动序列)。通过利用 CoT (Chain-of-Thought) 等提示技术逐步生成思维链。对于多步骤任务,则采用更复杂的规划工作流 (Search Workflows),如ToT (Tree-of-Thoughts)或基于MCTS (Monte Carlo Tree Search)的模拟搜索,以实现分层规划和路径探索。这些技术通过任务分解将复杂目标拆分为子任务序列。Action and Tool Calling:通过工具集 (Tool Set)获取了与外部世界交互的能力,弥补了 LLM 知识延后和缺乏实时性的局限。其核心在于Function Calling或Tool Calling API,通常以JSON等结构化方式维护参数。例如,Agent 可以使用RAG机制 来访问动态信息。一般采用ReAct (Reasoning and Acting)或Plan-and-Execute等框架,使 LLM 输出结构化的行动,从而实现自主工具使用,即 Agent 能够根据推理结果自主触发工具的使用。Feedback and Iteration Loop:反馈可以来自任务环境本身,工具或由人工评估提供。LLM-Profiled Evaluator (glmeval)在此发挥核心作用。在反馈学习工作流中,glmeval 提供反馈(可以是自由文本反射 或离散值分类),用于指导glmpolicy修订和重新生成整个决策,例如在 Reflexion 框架中进行“自我反思” 。通过采用长期记忆 (Long-Term Memory)(例如 RAG 和Episodic Buffers)来存储和检索上下文,支持持续学习,有效避免了 LLM 在固定上下文窗口 (Context Window) 下容易出现的灾难性遗忘 (Catastrophic Forgetting)问题。Output:当所有子任务完成或达到停止条件(如任务目标满足或迭代上限),Agent 使用总结提示来整合结果。这涉及多模态融合 (Multimodal Fusion) 如果有图像或数据输入,但在这里聚焦文本。五、未知与机遇——写给 2035 年的你
十年后,你打开手机,屏幕自动亮起:“早,昨晚我替你把 Q3 财报、孩子作业、父母体检报告全部跑完,还顺手帮你妈把社区团购砍价到 6 折。” 这就是 Andrej Karpathy 在 2024–2025 年连续 7 条 X 线程里反复强调的终极图景:Agent 不再是工具,而是你的人生操作系统。
他把未来拆成四层确定性:
1.2025–2026,超级 Copilot:3 行自然语言 → 42 节点可视化 Workflow,一键部署;
2.2027–2028,个人 OS:50 个微 Agent 常驻后台,每打开一个 App 就是一次“开小会”;
3.2029–2031,企业中枢:Agent Graph 取代 ERP,800 节点实时调度 3 万名员工;
4.2032–2035,文明级 MCTS:全球交互沉淀为共享记忆海洋,人与 AI 共用一个永不停歇的 ReAct 循环。
“LLM 是键盘,Agent 是电脑;键盘已死,电脑已活。”今天,你还需手动 Prompt;
明天,Agent 会替你写 Prompt;
后天,它会替你活。
我们不是在迎接 Agent 时代,我们只是提前 10 年搬进了它。
引用Attention Is All You Need:https://arxiv.org/abs/1706.03762
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding:https://arxiv.org/abs/1810.04805
Language Models are Few-Shot Learners (GPT-3):https://arxiv.org/abs/2005.14165
ReAct: Synergizing Reasoning and Acting in Language Models:https://arxiv.org/abs/2210.03629
Chain-of-Thought Prompting Elicits Reasoning in Large Language Models:https://arxiv.org/abs/2201.11903
Emergent Abilities of Large Language Models:https://arxiv.org/abs/2206.07682
Training Compute-Optimal Large Language Models (Chinchilla):https://arxiv.org/abs/2203.15556
Tree of Thoughts: Deliberate Problem Solving with Large Language Models:https://arxiv.org/abs/2305.10601
Reflexion: Language Agents with Verbal Reinforcement Learning:https://arxiv.org/abs/2303.11366
Voyager: An Open-Ended Embodied Agent with Large Language Models:https://arxiv.org/abs/2305.16291
LLM Powered Autonomous Agents (Lilian Weng 神文):https://lilianweng.github.io/posts/2023-06-23-agent/
AutoGPT 官方仓库:https://github.com/Significant-Gravitas/AutoGPT
BabyAGI 官方仓库:https://github.com/yoheinakajima/babyagi
LangChain 官方文档:https://python.langchain.com/docs/get_started/introduction
本文由 @天故有白 原创发布于人人都是产品经理。未经作者许可,禁止转载
题图来自Unsplash配资网址之家,基于CC0协议
华融配资提示:文章来自网络,不代表本站观点。
相关文章


沪深京指数
热点资讯




